体育游戏app平台不需要考据器渐渐遴荐-MK体育- MK体育官方网站- MK SPORTS


新智元报说念
剪辑:剪辑部 HNYZ
【新智元导读】仅凭测试时Scaling,1B模子竟完胜405B!多机构联手高明运用计较最优TTS计谋,不仅0.5B模子在数学任务上碾压GPT-4o,7B模子更是力压o1、DeepSeek R1这么的顶尖选手。
12日,一篇多机构纠合发表的论文,在AI圈引起震憾。
凭借再行想考计较最优的测试时Scaling,1B模子真的突出了405B?
跟着OpenAI o1诠释注解了测试时膨胀(TTS)不错通过在推理时辰派额外算力,大幅增强LLM的推理才智。测试时计较,也成为了现时栽植大模子性能的最新范式。
那么,问题来了:
在不同的计谋模子、进程奖励模子和问题难度级别下,怎样最优地膨胀测试时计较?
膨胀计较在多猛进度上不错提魁岸谈话模子在复杂任务上的推崇,较小的谈话模子能否通过这种方法已毕对大型模子的突出?
对此,来自清华、哈工大、北邮等机构的扣问东说念主员发现,使用计较最优TTS计谋,极小的计谋模子也不错突出更大的模子——
在MATH-500和AIME24上,0.5B模子的推崇优于GPT-4o;3B模子突出了405B模子;7B模子班师胜过o1和DeepSeek-R1,还具有更高的推感性能。

论文地址:https://arxiv.org/abs/2502.06703
这就标明,TTS是增强LLM推理才智的一种极有前途的方法。
同期,这也体现了扣问信得过的「弱到强」方法,而非现时的「强到弱」监督,对计谋优化的艰巨性。
再行想考「计较最优」的测试时Scaling
计较最优的膨胀计谋应当是奖励感知的
计较最优的测试时Scaling,旨在为每个问题分派最优计较资源。
字据此前的扣问,一种方法是使用单一的PRM手脚考据器在计谋模子的反映上进修PRM并将其用作考据器,以对团结计谋模子进行TTS;另一种方顺序是使用在不同计谋模子上进修的PRM来进行TTS。
从强化学习(RL)的角度来看,前者赢得的是在线PRM,后者则是离线PRM。
在线PRM能为计谋模子的反映产生更准确的奖励,而离线PRM由于散布外(OOD)问题经常会产生不准确的奖励。
关于计较最优TTS的本体运用而言,为每个计谋模子进修一个用于防御OOD问题的PRM在计较上是兴盛的。
因此,扣问东说念主员在更一般的开拓下扣问计较最优的TTS计谋,即PRM可能是在与用于TTS的计谋模子不同的模子上进修的。
关于基于搜索的方法,PRM辅导每个反映要领的遴荐,而关于基于采样的方法,PRM在生成后评估反映。
这标明:(1)奖励影响系数方法的反映遴荐;(2)关于基于搜索的方法,奖励还会影响搜索进程。
为分析这些要点,团队使用Llama-3.1-8BInstruct手脚计谋模子,RLHFlow-PRM-Mistral-8B和RLHFlow-PRM-Deepseek-8B手脚PRM,进行了一项初步的案例扣问。

奖励会显赫影响生成的进程和限度
RLHFlow-PRM-Mistral-8B对短反映予以高奖励,却产生了极度的谜底;而使用RLHFlow-Deepseek-PRM-8B进行搜索诚然产生正确谜底,但使用了更多token。
基于以上发现,扣问东说念主员建议奖励应该被整合到计较最优的TTS计谋中。将奖励函数默示为ℛ,奖励感知计较最优TTS计谋表述如下:
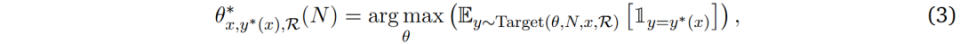
其中Target(𝜃, 𝑁, 𝑥, ℛ)默示在计较预算𝑁和指示词𝑥条款下,由奖励函数ℛ挪动的计谋模子𝜃输出散布。关于基于采样的膨胀方法,Target(𝜃, 𝑁, 𝑥, ℛ) = Target(𝜃, 𝑁, 𝑥)。
这种奖励感知计谋确保计较最优膨胀好像恰当计谋模子、指示词和奖励函数,从而为本体的TTS提供了一个更具普适性的框架。
皆备问题难度圭臬比分位数更有用
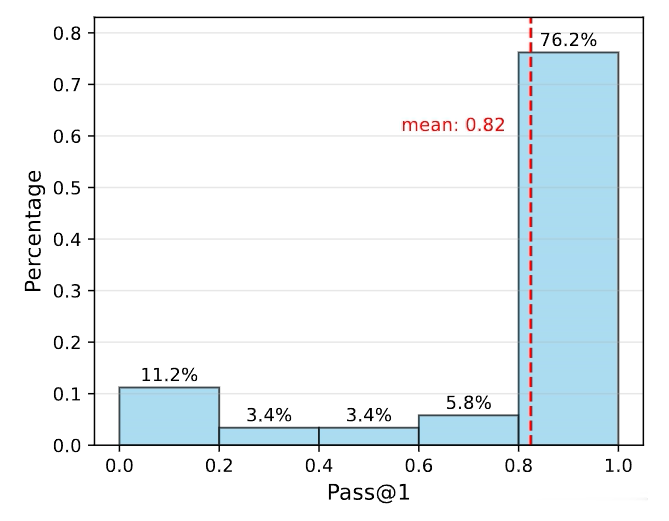
团队发现,使用来自MATH的难度等第或基于Pass@1准确率分位数的oracle标签并不有用,这是因为不同的计谋模子存在不同的推理才智。
如下图所示,Qwen2.5-72B-Instruct在76.2%的MATH-500问题上已毕了进步80%的Pass@1准确率。
因此,团队遴荐使用皆备阈值,而不是分位数来估计问题难度。即基于Pass@1准确率,界说三个难度等第:轻便(50%~100%)、中等(10%~50%)和困难(0%~10%)。
怎样最优地Scaling测试时计较?
Q1:怎样通过不同的计谋模子和PRM来栽植TTS?
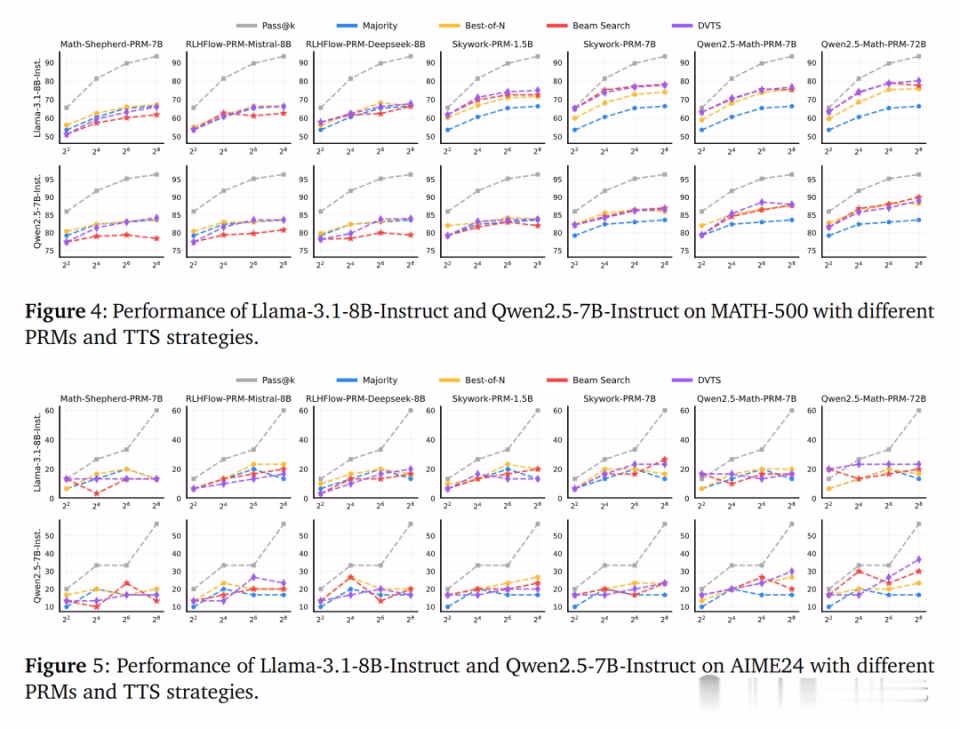
关于Llama-3.1-8B-Instruct模子,扣问团队使用Skywork和Qwen2.5-Math PRM的搜索方法在计较预算加多时性能显赫栽植,而使用Math-Shepherd和RLHFlow PRM的搜索方顺序限度较差。
关于Qwen2.5-7B-Instruct模子,使用Skywork-PRM-7B和Qwen2.5-Math PRM的搜索方法性能随计较预算加多而栽植,而使用其他的PRM性能仍然较差。
在AIME24数据集上,诚然两个计谋模子的Pass@k准确率跟着计较预算的加多而提高,但TTS的性能考订仍然有限。这标明PRM在不同计谋模子和任务间的泛化才智是一个挑战,尤其是在更复杂的任务上。
扣问团队发现当使用Math-Shepherd和RLHFlow PRM时,Best-of-N (BoN) 方法频繁优于其他计谋。而当使用Skywork和Qwen2.5-Math PRM时,基于搜索的方法推崇更好。
这种相反可动力于PRM在处治OOD(超出散布)计谋反映时限度欠安,因为PRM在不同计谋模子间的泛化才智有限。使用OOD PRM进行每一步的遴荐时可能会导致谜底堕入局部最优,从而裁减性能。
不外,PRM的基础模子也可能是一个影响成分,举例,使用Qwen2.5-Math-7B-Instruct进修的PRM比使用Mistral和Llama手脚基础模子的PRM泛化才智更好。
下图4和5诠释了PRM的遴荐关于TTS的限度至关艰巨,况且最好的TTS计谋会跟着使用的PRM的不同而转换,同期考据了PRM在不同计谋模子和数据集之间的泛化才智亦然一个挑战。
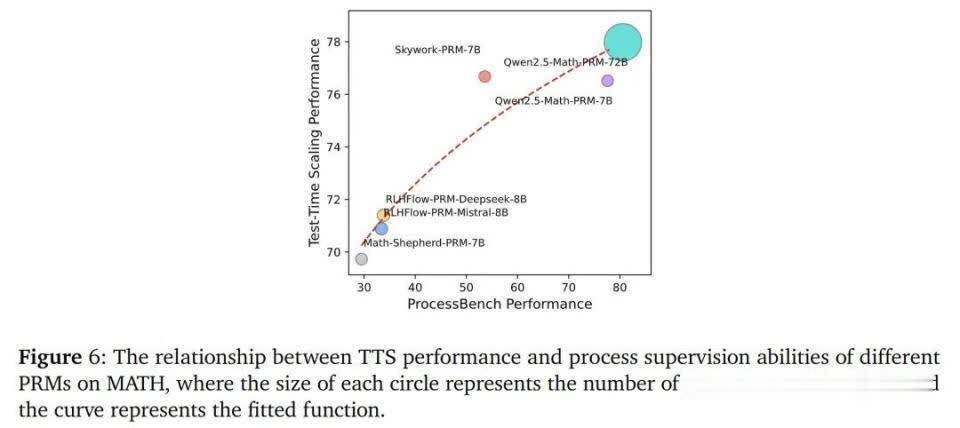
扣问团队发现,TTS的性能与PRM的进程监督才智之间存在正相关。具体来说,PRM的进程监督才智越强,其在TTS中频繁能带来更好的性能。
团队拟合了一个函数来样式这种关系,限度诠释了 PRM 的进程监督才智对TTS性能的艰巨性。
下图6标明,PRM的进程监督才智是决定其在TTS中性能的瑕玷成分。这为开拓更有用的PRM提供了标的:应该真贵提高PRM的进程监督才智,而不单是是加多参数目。
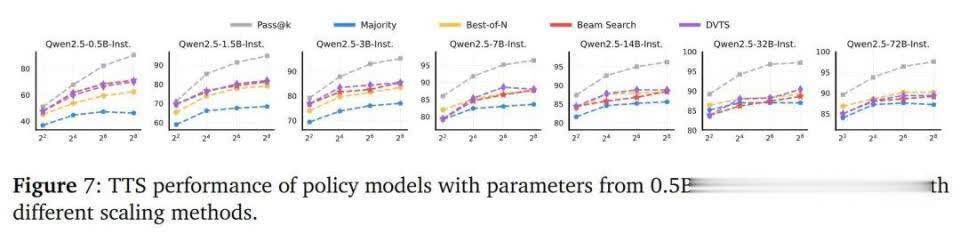
为特出到最优的TTS方法,扣问中使用了Qwen2.5系列的不同大小LLM(从0.5B到72B)进行现实。
限度清楚,关于微型计谋模子,基于搜索的方法优于BoN3。而关于大型计谋模子,BoN比基于搜索的方法更有用。
这可能是因为大型模子具有更强的推理才智,不需要考据器渐渐遴荐。而微型模子则依赖于考据器来遴荐每一步,以确保中间要领的正确性。
下图7标明最优的TTS方法依赖于计谋模子的大小,在遴荐TTS方法时需要筹商模子的推理才智。
Q2:TTS在不同难度问题上的考订情况怎样?
如前所述,团队基于Pass@1准确率的皆备值将难度级别分为三组:轻便(50%~100%)、中等(10%~50%)和困难(0%~10%)。
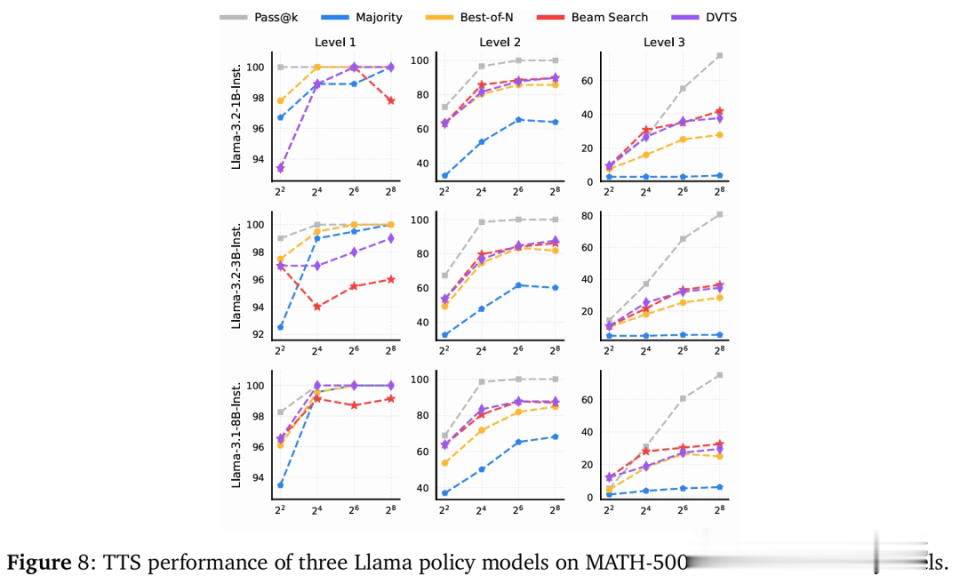
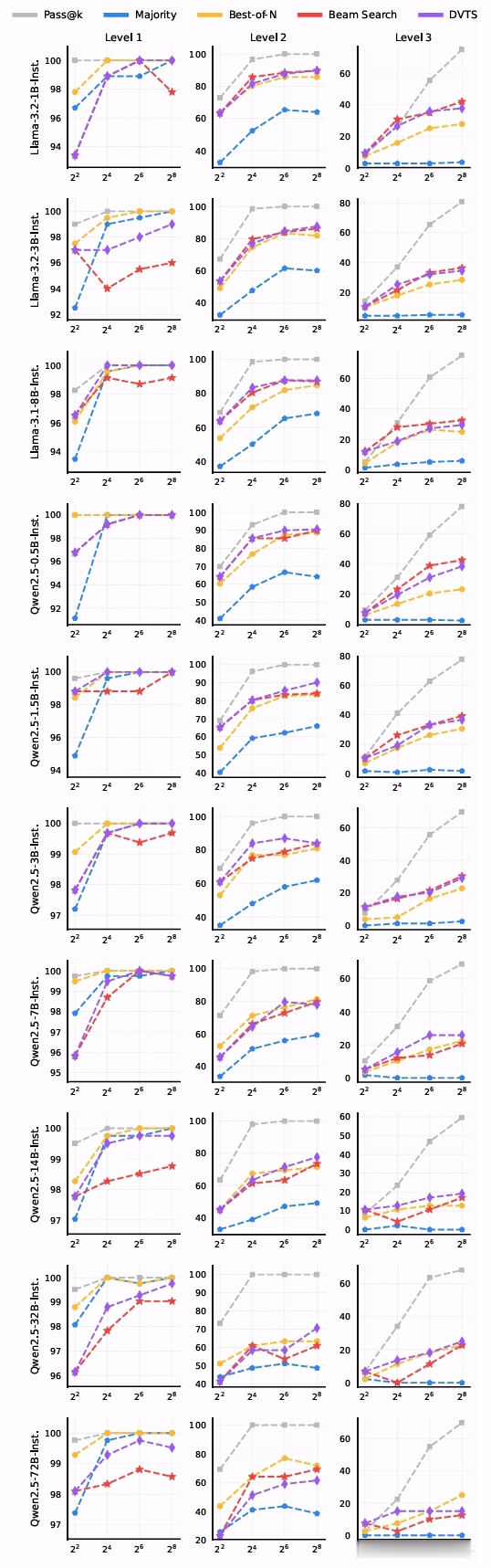
最优的TTS方法随难度级别的不同而变化,限度如下图所示。
关于小限制计谋模子(参数少于7B),BoN在轻便问题上推崇更优,而束搜索在较难问题上限度更好。
关于参数在7B到32B之间的计谋模子,DVTS在轻便和中等问题上推崇出色,而束搜索更相宜困难问题。
关于具有72B参数的计谋模子,BoN是适用于系数难度级别的最好方法。
高下滑动检察
Q3:偏好奖励模子PRM是否对特定反映长度存在偏差或对投票方法明锐?
PRM对要领长度存在偏差
扣问团队发现,即使在现实中使用疏浚的计较预算进行TTS,使用不同PRM在推理中产生的token数目相反显赫。
举例,在疏浚预算和疏浚计谋模子的情况下,使用RLHFlow-PRM-Deepseek-8B进行膨胀的推理token数目永恒比使用RLHFlow-PRM-Mistral-8B多近2倍。
这种相反与 PRM 的进修数据相关。RLHFlow系列PRM的进修数据来自不同的大谈话模子,这可能导致它对输出长度产生偏差。
为了考据这一不雅点,扣问团队分析了RLHFlow-PRM-Mistral-8B3和RLHFlow-PRM-Deepseek-8B4进修数据的几个特色。
如表1所示,DeepSeek-PRM-Data的每个反映平均token数和每个要领平均token数都大于Mistral-PRM-Data,这标明RLHFlow-PRM-Deepseek-8B的进修数据比RLHFlow-PRM-Mistral-8B的更长。这可能导致对输出长度的偏差。
扣问团队还发现,使用Qwen2.5-Math-7B进行膨胀的推理token数目大于使用Skywork-PRM-7B的数目,但性能特等接近,这标明使用Skywork-PRM-7B进行搜索更有用率。

PRM对投票方法具有明锐性
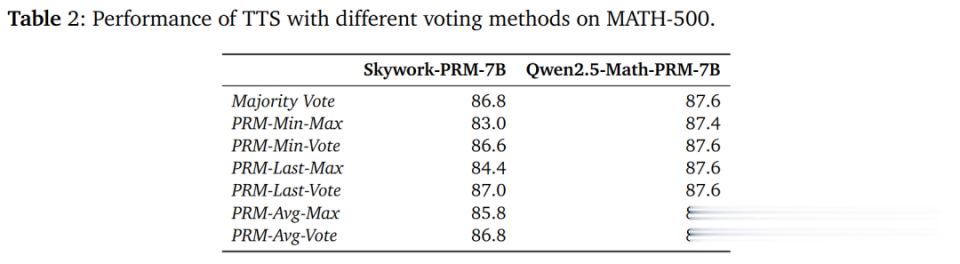
从表2的限度不错看出,Skywork-PRM-7B使用PRM-Vote比使用PRM-Max限度更好,而Qwen2.5-Math-PRM-7B对投票方法不太明锐。
这主若是因为Qwen2.5-Math PRM的进修数据经过了LLM-as-a-judge(将大谈话模子手脚判断器)处治,该处治移除了进修数据中被标识为正样本的极度中间要领,使得输出的高奖励值更可能是正确的。
这标明PRM的进修数据对栽植其在搜索进程中发现极度的才智具有艰巨意旨。
「计较最优」的测试时Sclaing
在计较最优TTS计谋下,扣问东说念主员就另外三大问题,进行了现实评估。
Q4:较小的计谋模子,能否在计较最优TTS计谋下优于较大的模子?
对微型计谋模子进行测试时计较的膨胀,对栽植LLM的推感性能至关艰巨。
那么,较小的计谋模子能否通过计较最优的TTS计谋,突出更大的模子,如GPT-4o、o1、DeepSeek-R1?
如下表3所示,扣问东说念主员得出了4点瑕玷的细察:
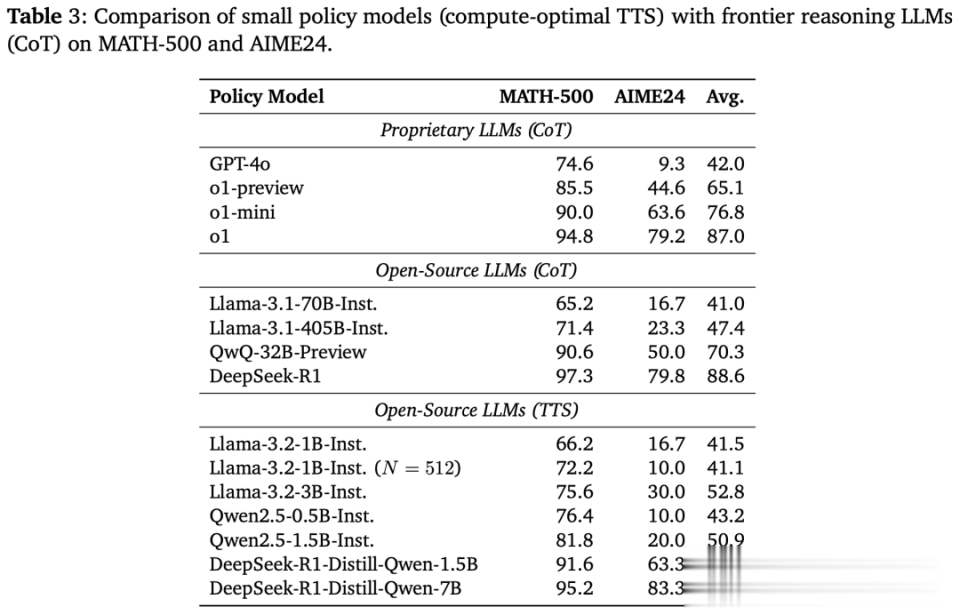
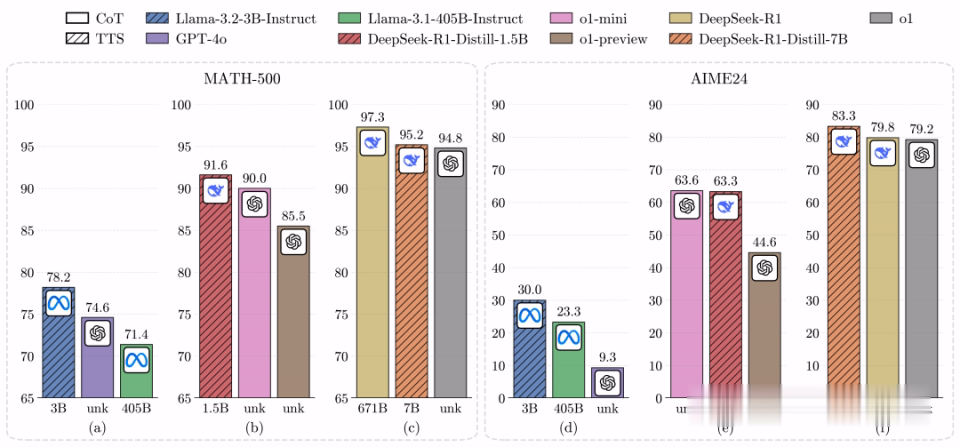
1. 禁受计较最优TTS计谋后,在两大数学基准MATH-500和AIME24上,Llama-3.2-3B-Instruct性能碾压Llama-3.1-405B-Instruct。
从这点不错看出,较小模子通过计较最优TTS计谋,可突出大135倍的模子。
与此前谷歌Charlie Snell团队等TTS相关扣问比拟,新方法将限度栽植了487.0%(23倍→135倍)。
2. 将计较预算加多到N=512,相通禁受计较最优TTS的Llama-3.2-1B-Instruct,在MATH-500基准上打败了Llama-3.1-405B-Instruct。
奇怪的是,在AIME24上,它的性能又不如Llama-3.1-405B-Instruct。
3. 禁受计较最优TTS,Qwen2.5-0.5B-Instruct、Llama-3.2-3B-Instruct均突出了GPT-4o。
这标明,小模子不错通过计较最优TTS计谋,也能一举突出GPT级别的大模子。
4. 在相通计谋和基准下,DeepSeek-R1-Distill-Qwen-1.5B竟能碾压o1-preview、o1-mini。
同期,DeepSeek-R1-Distill-Qwen-7B还能打败o1和DeepSeek-R1。
以上这些限度标明,经过推理增强的小模子不错,通过计较最优TTS计谋突出前沿推理大模子。
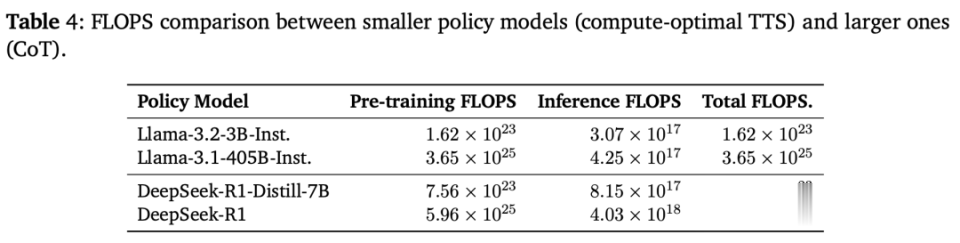
再来看下这些模子FLOPS比较,如下表4所示,微型计谋模子即使在使用更少推理FLOPS的情况下,也能突出大型模子,并将总FLOPS减少了100-1000倍。
Q5:计较最优TTS与CoT和无数投票比拟有何考订?
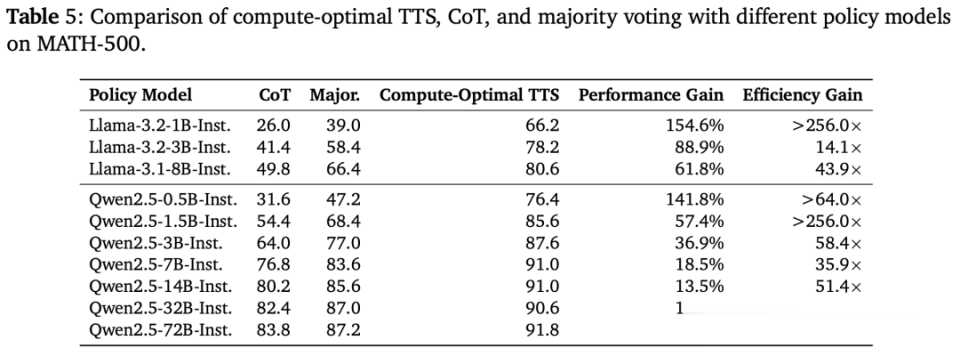
如下表5展示了,每个计谋模子在MATH-500上的计较最优TTS限度。
限度发现,计较最优TTS的效劳不错比无数投票高256倍,况且比拟CoT栽植了154.6%的推感性能。
这些限度标明,计较最优TTS显赫增强了LLM的推理才智。
但是,跟着计谋模子参数数目的加多,TTS的考订限度渐渐减小。这标明,TTS的有用性与计谋模子的推理才智班师相关。
具体来说,关于推理才智较弱的模子,Scaling测试时计较会带来显赫考订;而关于推理才智较强的模子,栽植限度则较为有限。
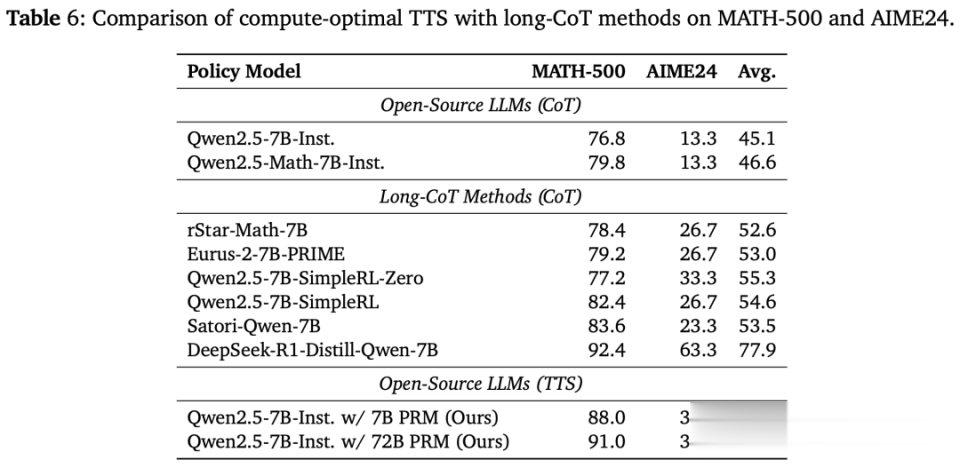
Q6:TTS是否比基于长CoT的方法更有用?
如下表6所示,扣问东说念主员发现,在MATH-500和AIME24基准上,使用Qwen2.5-7B-Instruct的TTS都优于rStar-Math、Eurus-2、SimpleRL和Satori。
但是,诚然TTS在MATH-500上的推崇,接近DeepSeek-R1-Distill-Qwen-7B,但在AIME24上推崇出彰着下落。
这些限度标明,TTS比班师在MCTS生成数据上,运用RL或SFT的方法更有用,但不如从弘远的推理模子中进行蒸馏的方法有用。
另外,TTS在较轻便的任务上,比在更复杂的任务上更有用。
作家先容
Runze Liu

Runze Liu是清华大学深圳国外扣问生院的二年齿硕士生,导师是Xiu Li教训。他曾于2023年6月赢得山东大学的荣誉学士学位。
当今,他也在上海AI Lab大模子中心担任扣问实习生,由Biqing Qi博士辅导。
Runze Liu的扣问重心是大模子和强化学习(RL)。当今,他对提魁岸模子的推理和泛化才智特别感兴致体育游戏app平台,同期也在探索将大模子整合以增强RL算法的后劲,特别是在东说念主类/AI反馈强化学习(RLHF/RLAIF)情况下。